Im Bereich der akkreditierten Umweltanalytik sind sehr oft auch die AQS-Merkblätter der Bund/Länder-Arbeitsgemeinschaft Wasser (LAWA) maßgeblich, insbesondere, wenn man im Fachmodul Wasser unterwegs ist. Das 2018 überarbeitete AQS-Merkblatt P3/1 “Bestimmung der Elemente in Wässern mit der ICP-OES” fordert im Anhang einen Linearitätstest nach DIN 38402-51 für die Kalibrierung. Ist dieser Test nicht in den schon genutzten Laborsoftware-Paketen (LIMS, Gerätesoftware etc.) enthalten, dann heißt es Excel-Vorlagen nutzen (Arbeitshilfen der wasserchemischen Gesellschaft) oder anderweitig selbst machen. Hier möchte ich eine Python-Version zur normkonformen Darstellung des Linearitätstests vorstellen.
Zuerst einmal legen wir los mit den obligatorischen Import Statements. Für diese Darstellung benötigen wir u.a.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sigfig import round
Gehen wir mal davon aus, dass wir uns die Werte aus dem LIMS oder über einen sonstigen Export in eine XLSX Datei ausgeben lassen, welches für dieses Beispiel z.B. so ausschaut (Daten entsprechen dem Testdatensatz der DIN):
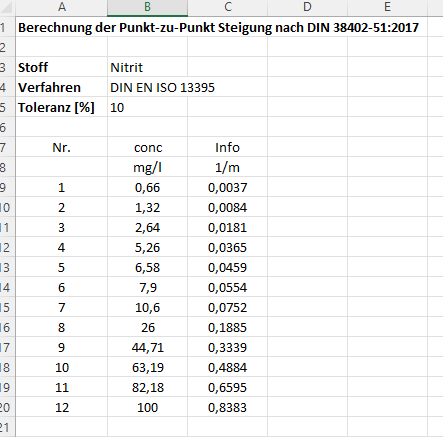
Dieses XLSX muss nun erst einmal in ein pandas-DataFrame hinein, um es gut weiterverarbeiten und plotten zu können:
# Excel-File Einlesen
df = pd.read_excel("data/punkt_zu_punkt.xlsx", skiprows=1, names=['Nr','x','y'])
df.head()
| Nr | x | y | |
|---|---|---|---|
| 0 | Stoff | Nitrit | NaN |
| 1 | Verfahren | DIN EN ISO 13395 | NaN |
| 2 | Toleranz [%] | 10 | NaN |
| 3 | NaN | NaN | NaN |
| 4 | Nr. | c | Ext. |
Noch enthält das DataFrame Informationen wie den Stoffnamen, das Verfahren und die akzeptierte Toleranz für den Linearitätstest (10% entsprechend AQS MB P3/1). Diese Angaben haben im DataFrame eigentlich nix zu suchen, da dort später nur die Konzentrationslevel und Messwerte übrig bleiben sollen. Dementsprechend muss alles noch aufbereitet werden. Einfach droppen können wir die Zeilen 0 – 3 nicht, da wir die darin enthaltenen Infos noch benötigen. Also werden diese vor dem Drop in Variablen übernommen:
# Verfahren, Einheit und Toleranz auslesen und dann DF vorbereiten
stoff = df.iloc[0, 1]
verfahren = df.iloc[1, 1]
toleranz = df.iloc[2, 1]
einheit = df.iloc[5, 1]
df.dropna(inplace=True)
df.drop([4], inplace=True)
df.reset_index(inplace=True)
df.drop(labels=['index', 'Nr'], axis=1, inplace=True)
df.x = pd.to_numeric(df['x'])
df.y = pd.to_numeric(df['y'])
df.head()
| x | y | |
|---|---|---|
| 0 | 0.66 | 0.0037 |
| 1 | 1.32 | 0.0084 |
| 2 | 2.64 | 0.0181 |
| 3 | 5.26 | 0.0365 |
| 4 | 6.58 | 0.0459 |
Jetzt haben wir die Daten in einem Format, in welchem wir bequem weiterarbeiten können. Zuerst einmal berechnen wir die Punkt-zu-Punkt Steigung iterativ über das DataFrame in eine neue Spalte mit der Bezeichnung “m”. Dies entspricht einer fortlaufenden Bildung des jeweiligen x,y-Differenzquotienten 
# Punkt-zu-Punkt Steigung berechnen
for i in range(len(df)-1):
df.loc[i,'m'] = (df.loc[i+1, 'y'] - df.loc[i, 'y'])/ (df.loc[i+1, 'x'] - df.loc[i, 'x'])
df.head(5)
| x | y | m | |
|---|---|---|---|
| 0 | 0.66 | 0.0037 | 0.007121 |
| 1 | 1.32 | 0.0084 | 0.007348 |
| 2 | 2.64 | 0.0181 | 0.007023 |
| 3 | 5.26 | 0.0365 | 0.007121 |
| 4 | 6.58 | 0.0459 | 0.007197 |
Ein paar weitere benötigte Daten wie Median und die Akzeptanzgrenzen für das Vorliegen von Linearität lassen sich direkt berechnen. Hierzu wird der Median der Steigung sowie die Differenz der Punkt-zu-Punkt Steigung von diesem Steigungsmedian benötigt. Diese Differenz landes in der Spalte “delta”:
median = df.m.median()
df['delta'] = df.m - median
limit_upper = median * (toleranz / 100)
limit_lower = limit_upper * (-1)
Nun ist es an der Zeit sich um die eigentliche Regression zu kümmern. Hierzu wird über numpy-Polyfit eine lineare Regression durchgeführt und über die dann zugängliche Geradengleichung werden die passenden y-Werte zu den Konzentrationsleveln der Kalibrierung berechnet. Diese landen in der neuen Spalte “y_reg”:
# Regression rechnen
m_reg, b_reg = np.polyfit(df.x, df.y, 1)
# reg_add wird zur String-Darstellung der Geradengleichung benötigt
if b_reg < 0:
reg_add = "-"
b_reg_disp = b_reg * (-1)
else:
reg_add = "+"
b_reg_disp = b_reg
df['y_reg'] = m_reg * df.x + b_reg
df.head()
| x | y | m | delta | y_reg | |
|---|---|---|---|---|---|
| 0 | 0.66 | 0.0037 | 0.007121 | -0.000227 | -0.005299 |
| 1 | 1.32 | 0.0084 | 0.007348 | 0.000000 | 0.000117 |
| 2 | 2.64 | 0.0181 | 0.007023 | -0.000326 | 0.010948 |
| 3 | 5.26 | 0.0365 | 0.007121 | -0.000227 | 0.032446 |
| 4 | 6.58 | 0.0459 | 0.007197 | -0.000152 | 0.043277 |
Für den späteren Plot wäre es schön, einen tabellarischen Ausdruck der verwendeten Daten zu haben. Diese werden dazu in einem neuen DataFrame für den Plot aufbereitet. Anhand der Toleranz wird auch direkt entscheiden, ob ein Kalibrierlevel noch als Linear zu betrachten ist:
# neues DF für tabellarische Darstellung aufbereiten
df_tab = df.copy()
df_tab.drop("y_reg", axis=1, inplace=True)
nr_list = [int(x+1) for x in range(len(df_tab))]
df_tab.insert(0, 'Lfd. Nr', nr_list)
df_tab.reset_index()
df_tab = df_tab.round(decimals=5)
df_tab["Wert Linear"] = np.where(df_tab.delta.abs() < limit_upper, "Ja", "Nein")
df_tab.rename(columns={
'x': f'Konz. [{einheit}]',
'y': 'Messwert',
'm': 'P-P Steigung',
'delta': ' zum Median'},
inplace=True)
df_tab.head()
zum Median'},
inplace=True)
df_tab.head()
| Lfd. Nr | Konz. [mg/l] | Messwert | P-P Steigung | zum Median |
Wert Linear | |
|---|---|---|---|---|---|---|
| 0 | 1 | 0.66 | 0.0037 | 0.00712 | -0.00023 | Ja |
| 1 | 2 | 1.32 | 0.0084 | 0.00735 | 0.00000 | Ja |
| 2 | 3 | 2.64 | 0.0181 | 0.00702 | -0.00033 | Ja |
| 3 | 4 | 5.26 | 0.0365 | 0.00712 | -0.00023 | Ja |
| 4 | 5 | 6.58 | 0.0459 | 0.00720 | -0.00015 | Ja |
Jetzt liegt alles aufbereitet vor, was zum Plotten benötigt wird. Also los:
fig = plt.figure(figsize=(10,10))
fig.suptitle(f"Linearitätstest nach DIN 38402-51:2017-05 (A51) \n für die Bestimmung von {stoff} nach {verfahren}")
ax0 = plt.subplot(2,1,1)
tabledata = ax0.table(cellText=df_tab.values, colLabels=df_tab.columns, loc='center', cellLoc='center')
tabledata.auto_set_column_width(0)
tabledata.auto_set_font_size(False)
tabledata.set_fontsize(9)
ax1 = plt.subplot(2,2,3)
ax1.scatter(df.x, df.y, s=10, color='r')
ax1.plot(df.x, df.y_reg, label=f'y={m_reg:.4f}x {reg_add} {b_reg_disp:.4f}')
ax1.set_xlabel(f'{stoff} [{einheit}]')
ax1.legend()
ax1.set_ylabel('Signal')
ax2 = plt.subplot(2,2,4)
ax2.stem(df.index, df.delta, linefmt='b', markerfmt='s')
ax2.axhspan(limit_lower, limit_upper, color='g', alpha=0.2)
ax2.set_xlabel("Kalibrier-Level")
plt.tight_layout()
Ausführen des Scripts ergibt dann folgenden Plot:
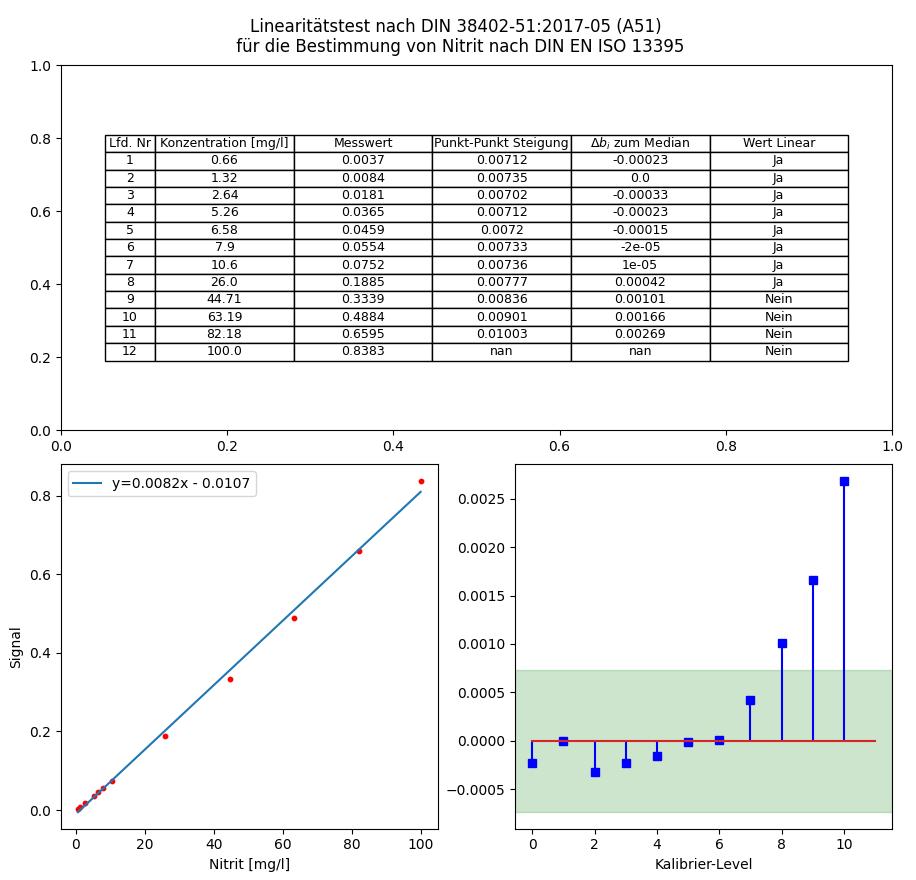
Das Resultat entspricht ziemlich exakt der Darstellung des DIN-Testdatensatzes in der DIN 38402-51 und dieses Vorgehen lässt sich gut mit einem Script automatisieren.